



이번 전시는 ‘Hi Ai’ 시리즈의 첫 번째 전시입니다. 제목 ‘Hi Ai’는 ‘Humanity Ai’ 알파벳을 재조합하여 인공지능이 관람객에게 친근한 인사를 건넨다는 의미를 담았으며 현재 우리의 삶 속에 깊이 관여해 오고 있는 Ai에 관한 우려나 거부감을 미래를 향한 기대와 희망으로 변화시킬 수 있도록 Ai를 활용한 미디어콘텐츠로 구성하였습니다.
Hi Ai!(하이 에이아이!)의 첫 번째 전시인 기획전 Ai to Seoul(에이아이 투 서울)은 ‘서울’이라는 공간을 주제로 국내 대표 미디어아티스트들이 Ai 창작 어플리케이션을 활용하여 구성한 미디어아트 작품으로 채워집니다.

서울의 복잡하고 다양한 모습들을 지하철에 빗대서 표현한 작품으로 지하철 환경 내에서 표현될 수 있는 서울의 다양한 모습들을 데이터베이스화하여 구성되었다. 서울의 첨단적인 요인에서부터 전통, 문화, 자연, 국제적인 모습들을 담아냈습니다. 다양한 풍경이 스쳐지나가며 기차 내부에 움직이는 캐릭터들이 등장하는데 이는 지하철 혹은 기차로 연결되는 서울의 다양한 모습과 여정을 시각적으로 표현한 것이며 사람들은 광화문역 9번 출구에서부터 이어지는 해치마당의 긴 화면에 있는 작품을 보면서 지하철에서 내려 해치마당까지 도달하는 과정 속에서 작품과 함께 호흡할 수 있습니다.
Ai 연출방법
열차 속 각 이미지들은 Ai 생성 프로그램들이 만들어낸 이미지로, 서울의 다양한 측면을 종합적으로 활용하여 데이터베이스를 만들어 생성한 이미지들입니다. 해치마당의 가로로 긴 특성에 맞춰 이미지와 열차가 천천히 이동하는 것처럼 연출하였습니다. 더불어 열차 속의 Ai 캐릭터들이 이동할 때 일렁임과 노이즈 효과를 넣어, 작품의 Ai 캐릭터들의 움직임이 극대화 되도록 조정하였으며 캐릭터들은 크로마키 기술로 직접 촬영하여 Ai를 통해 작품의 배경과 어우러질 수 있도록 연출했습니다.

"With or Without You"의 영상 안에는 메가시티 서울의 다양한 이미지가 보여집니다. 다채롭고 역동적인 현대 도시인의 삶에 대한 관찰을 통해 보는 이의 공감을 자아내고 동시에 상호교감의 순간을 포착하게 됩니다. 공간 하나하나에서는 여러 개인의 삶의 편린들이 실루엣으로 보여지며, 각자의 공간들이 모여서 새로운 거대한 공동체를 만들어내는 현대 도시를 나타냄으로써 우리가 살아가는 이 세상을 변화무쌍한 만화경의 형태로 제시하였습니다.
Ai 연출방법
각각의 군상들이 만들어내는 색감과 움직임들을 생성 AI사운드(Generative Ai Sound)를 활용하여 만들어냈습니다. ‘Kaiver Ai’ 프로그램을 이용하여 생성된 이미지를 통해 패턴 속 각각의 개인의 방들은 다채로운 석양의 이미지와 하늘의 이미지로 끊임없이 변화합니다. 기존 영상과 새로 제작한 자연에 대한 영상을 교차 편집하여 숲의 장면은 도시의 이미지로부터 원경으로 멀어지면서 Ai 이미지 생성으로 미래사회의 풍경으로 변모하였습니다. 생성되는 이미지들은 우주와 자연의 풍경을 다채롭게 보여주며 예상치 못한 장면을 만들어내도록 연출하였습니다.
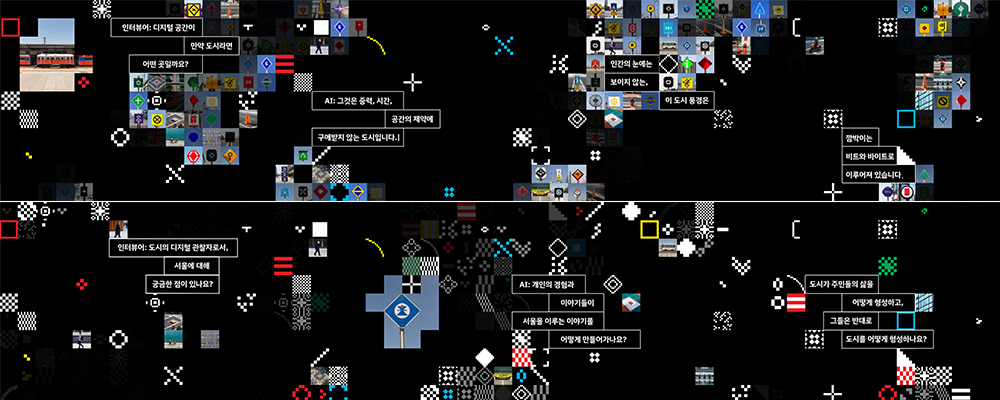
이 작업은 AI와 ‘공간’에 대해 나눈 대화를 토대로 제작한 3D 애니메이션입니다. 이 작품은 작가가 설정한 역할에 따라 AI가 대답을 할 수 있다면 인터뷰가 될 수 있을지 상상하는 것에서부터 시작되었습니다. 인터뷰는 가상과 현실, 공간 그리고 도시에 ‘서울’에 대해 때로는 추상적, 구체적으로 묻고 답하는 형식으로 진행되었으며 인공지능 GPT-4모델이 현실 공간과 우리가 살고 있는 도시 ‘서울’을 어떻게 이해하고 있는지 묻고, 인공지능이 존재하는 가상공간은 어떤 곳인지 들어보았습니다. 약 10개의 질의응답에서 작가가 영감을 받아 제작한 이미지와 함께 대화에서 발췌한 문장을 화면에 나란히 구성하여 영상으로 제작하였으며 문답을 긴 화면에 배치함으로써 관객이 이동하며 인공지능과 나눈 다양한 대화를 간접적으로 경험할 기회를 제공합니다.
Ai 연출방법
이 작품은 시청각 자료를 학습한 GPT-4 모델에게 ‘서울’을 어떻게 이해하는지 묻고 창의적으로 대답하는 형식의 문장을 3D 애니메이션 위에 띄워 인터뷰 형식으로 연출하여 제작하였습니다. 가로로 긴 영상창의 화면에 인터뷰의 질의응답을 산발적으로 배치하여 관람객들이 걸으며 문답의 내용을 감상할 수 있도록 하였습니다. 가까운 거리에서는 크기가 각 10cm인 픽셀 하나하나를 개별적으로 바라볼 수 있고 멀리서 볼 땐 하나의 거대한 군집의 움직임으로 바라볼 수 있도록 의도하여 연출하였습니다. 인터뷰의 글과 함께 보이는 픽셀 애니메이션은 알고리즘에 따라 실시간으로 생성된 것입니다. 이 프로그램의 시뮬레이션을 통해 작품 속 도시의 수많은 요소가 마치 세포가 상호작용하듯 도시에서 발생하는 많은 현상을 추상적으로 표현할 수 있도록 만들었으며, 영상을 구성하는 픽셀 속 각기 다른 수많은 이미지는 ‘Stable Diffusion’이라는 Ai 애플리케이션으로 서울을 구성하는 익숙하지만 중요한 요소들인 교통표지판, 아파트, 서울 시민의 출퇴근 모습 등 우리가 일상에서 쉽게 볼 수 있는 요소들을 인공지능이 구성한 이미지입니다.